網頁來說,主要有動態網頁與靜態網頁的差別.
動態網頁的部分,則可利用RSelenium來進行動態頁面的抓取.
(這部分,留給不知道還有多久的將來,再行回過頭補充吧!)
靜態網頁,可利用以下介紹的方式進行作業.
爬蟲的流程可分為Connection(連接)和Parsing(解析)兩階段.
主要R語言分別使用的套件:
相關連結與解析用的函數:
相關連結與解析用的函數:
本專案將以xml2套件,進行實作,在此將前步驟所觀察到的各式所需結果,帶入程式碼當中。
首先,專案的目的當然是要爬回所有分頁的資料,在此之前,當然要知道共計有多少分頁.
因此,就先來處理已經顯示在頁面上的總頁數,當作小試身手,也為下步驟做準備.
(本步驟除更新外,僅需安裝一次。)
#處理所需套件Package
install.packages("xml2")
#處理所需套件library
library(xml2)
本專案預計資料將暫時落地為csv檔,先行處理預設工作目錄。
#處理工作檔案位置
wdpath=paste0(getwd(),"/Documents/")
基本上,站台跟節點都是分開處理,要根據需要兜成一完成路徑,才可使用.
後續,仍有其他的作業將沿用相關設定.
這邊注意使用的是paste0()的函數,請自行比較跟?paste.
最後一行,是直接連結上網站,將網頁整體內容抓回來,放到doc中.
#處理網址
web.url="https://join.gov.tw"
base.url=paste0(web.url,"/idea/index/search/ENDORSING?page=")
doc <- read_html(base.url)
可以用View(doc)查看一下結果,基本上是把整個對應網頁的header,body爬回來了!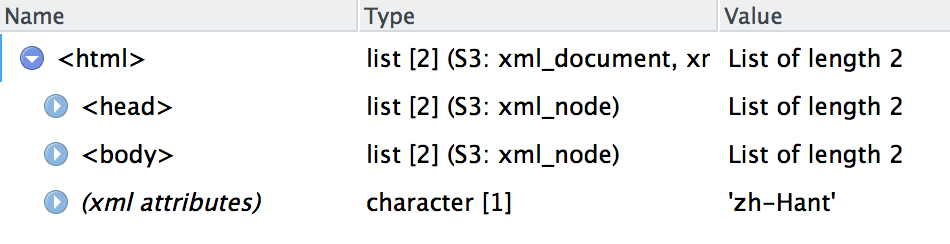
給定xpath總頁碼對應的xpath節點
用xml_find_all爬出該xpath對應位置
接著用xml_text抓出對應值
最後用處理字串,將"1/"去掉,僅留下我們要的資料.
補充提醒:練習階段,會將總頁碼給定較小的值,便於後續習作
#處理頁碼
xpath.bonus <- "//*[@id='naviPageForm']/ul/li[2]/span"
totalpage <- xml_text(xml_find_all(doc, xpath.bonus))
totalpage<-sub("1 / ","",totalpage)
# 練習時僅執行兩頁 totalpage<-2
有部分網站,沒有總頁數可以爬抓,可利用其他方法,測試總頁數,得到相同結果.


